Dataset and pretrained models¶
If you want to use your own training data, please use OnClass_data_public_minimal.tar.gz. OnClass_data_public_minimal.tar.gz includes the minimal files (ontology files) needed to run OnClass on your own dataset. You need to provide the annotated cells (training data) and then OnClass can classify unannotated cells.
If you don’t have your own training data, you can use the annotated gene expression data (e.g., Tabula Muris Senis, Lemur, HLCA, Allen brian) used in OnClass paper or pretrained models. See scRNA_data below for how to download the annotated gene expression data. See Pretrained_model below for how to download the pretrained model.
1) scRNA_data¶
Download three parts from link 1, link 2, link 3. Jointly extract the files using
cat OnClass_data_public_scRNA_data.tar.gz.* | tar -xz
This will give you all the single cell gene expression data used in our paper (see Fig. 2, Extended Data Figs. 1-3, Supplementary Figs. 4-7).
2) Ontology_data¶
These files are in OnClass_data_public_minimal.tar.gz. They include Cell Ontology and Allen brain Ontology. Cell Ontology has cell type text definition. cl.ontology.nlp.emb is the text embedding of the definition of each cell type.
3) Pretrained_model¶
Download 8 tensorflow pretrained models here. They are trained from 8 dataset in Fig. 2, Extended Data Figs. 1-3, Supplementary Figs. 4-7.
4) Intermediate_files¶
This folder contains the intermediate files. Data generated by example scripts will be stored here.
We suggest you organize all the downloaded files as the following:
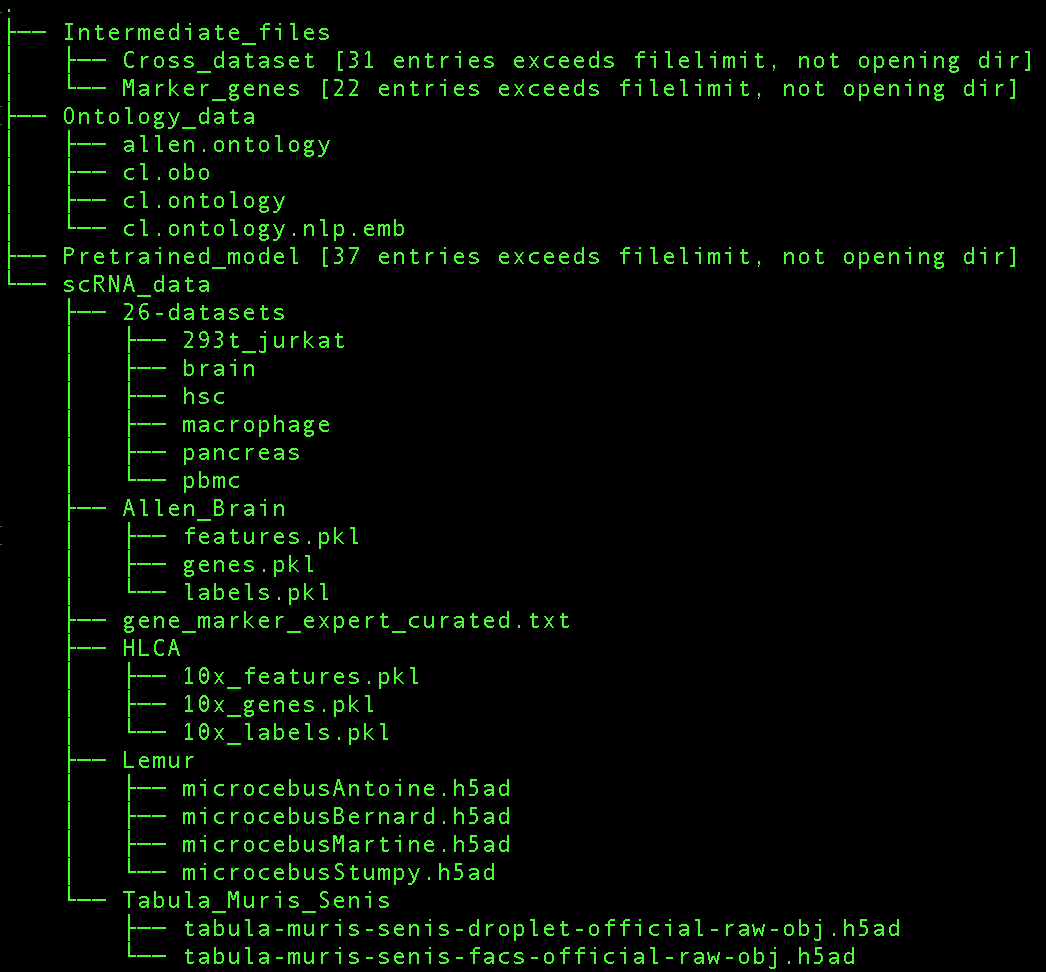
For questions about the datasets, please contact Sheng Wang at swang91@uw.edu.